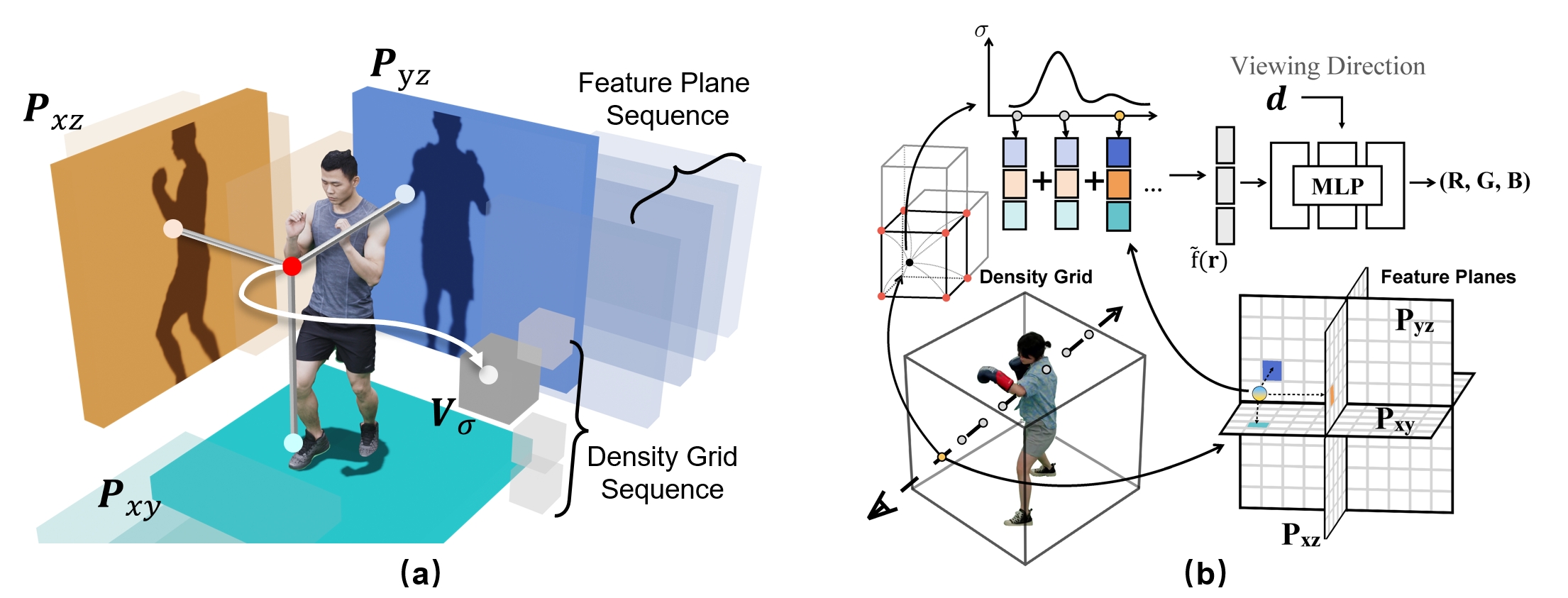
Neural Radiance Fields (NeRF) revolutionize the realm of visual media by providing photorealistic Free-Viewpoint Video (FVV) experiences, offering viewers unparalleled immersion and interactivity. However, the technology's significant storage requirements and the computational complexity involved in generation and rendering currently limit its broader application. To close this gap, this paper presents Temporal Tri-Plane Radiance Fields (TeTriRF), a novel technology that significantly reduces the storage size for Free-Viewpoint Video (FVV) while maintaining low-cost generation and rendering. TeTriRF introduces a hybrid representation with tri-planes and voxel grids to support scaling up to long-duration sequences and scenes with complex motions or rapid changes.
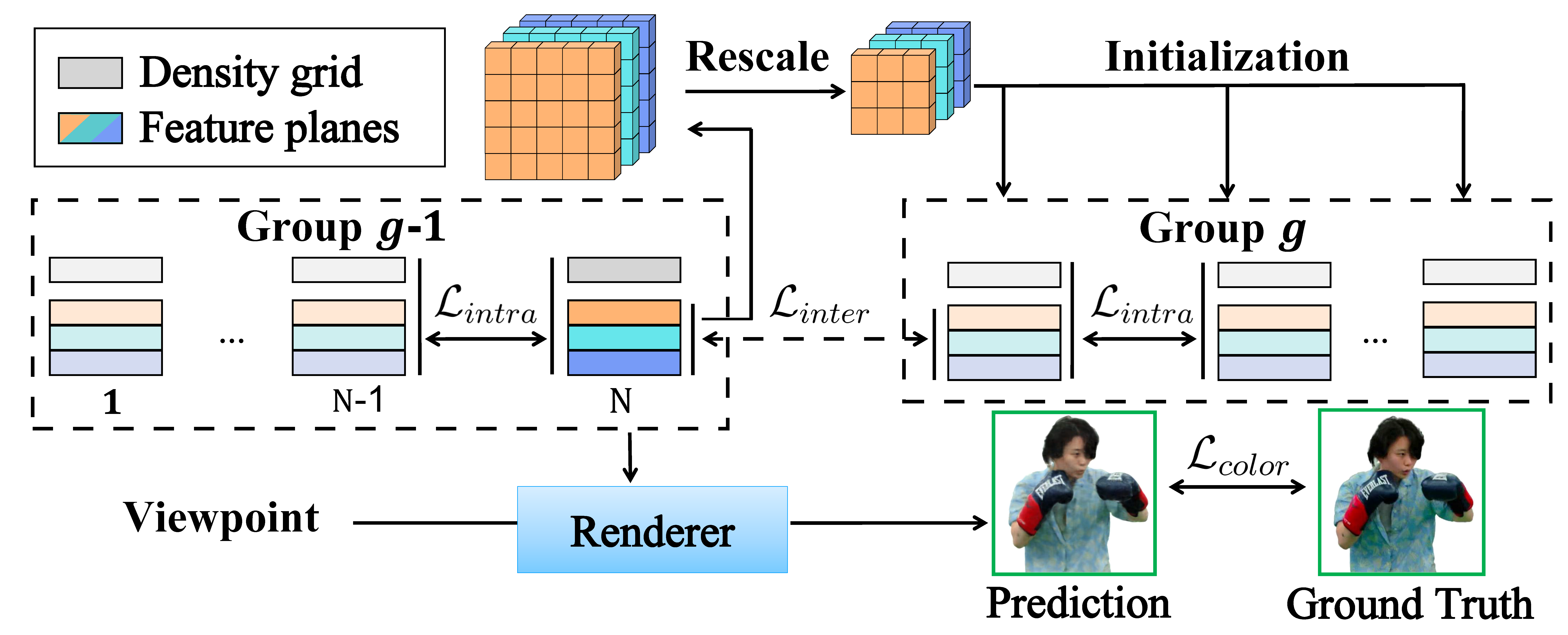
We propose a group training scheme tailored to achieving high training efficiency and yielding temporally consistent, low-entropy scene representations.
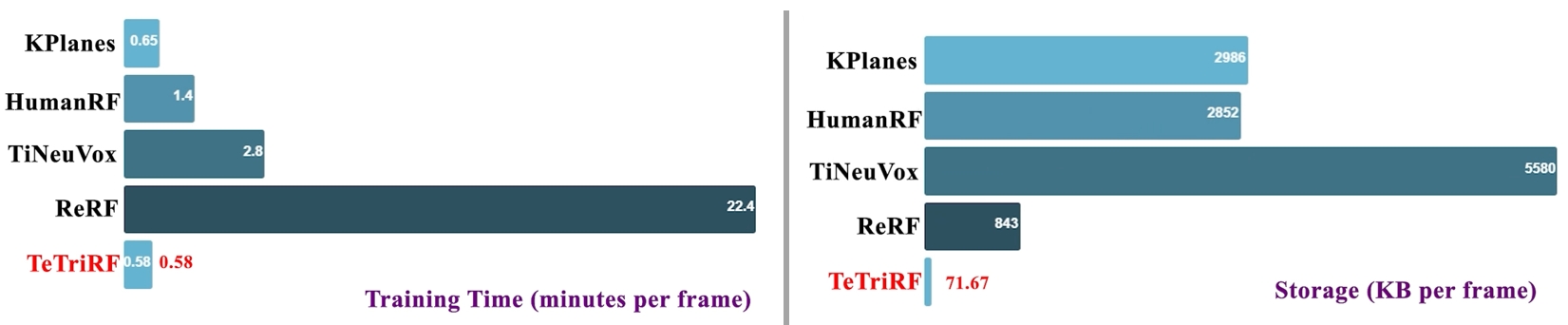
Leveraging these properties of the representations, we introduce a compression pipeline with off-the-shelf video codecs, achieving an order of magnitude less storage size compared to the state-of-the-art.
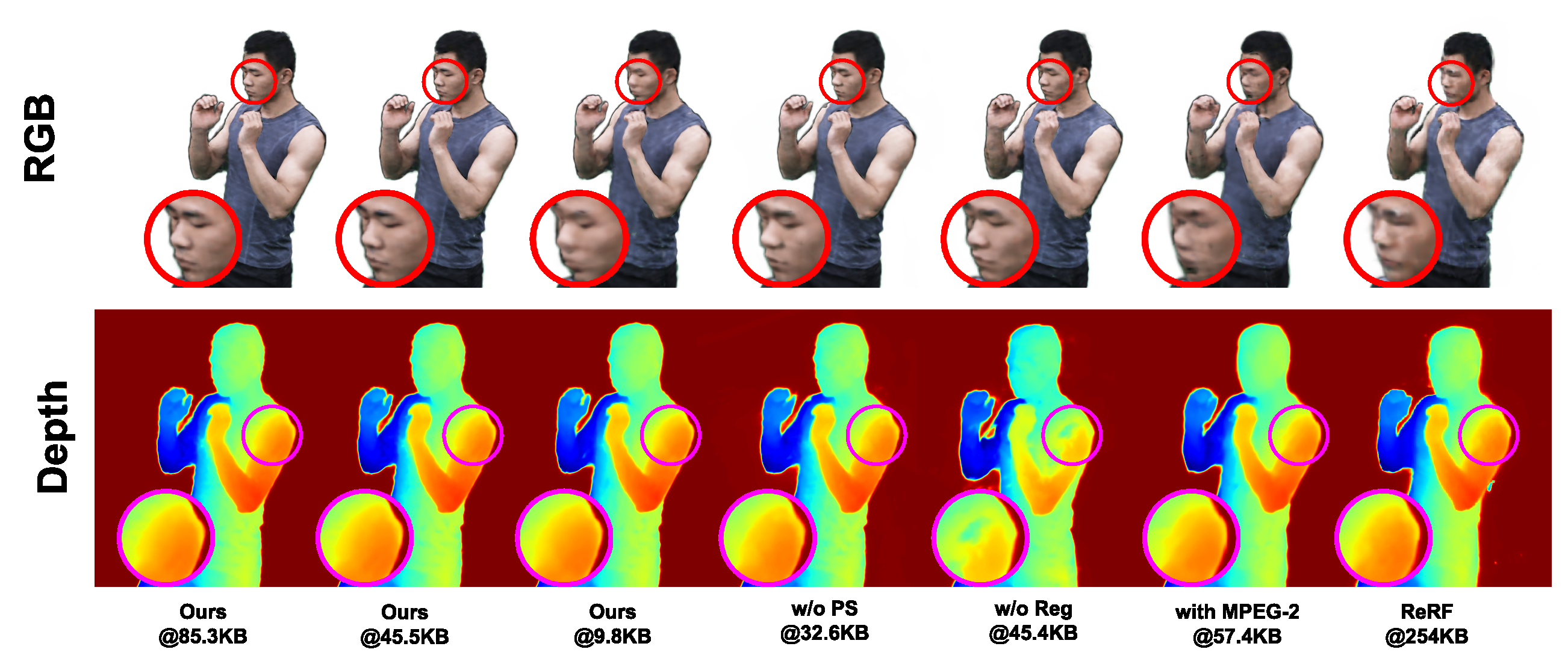
Our experiments demonstrate that TeTriRF can achieve competitive quality with a higher compression rate.