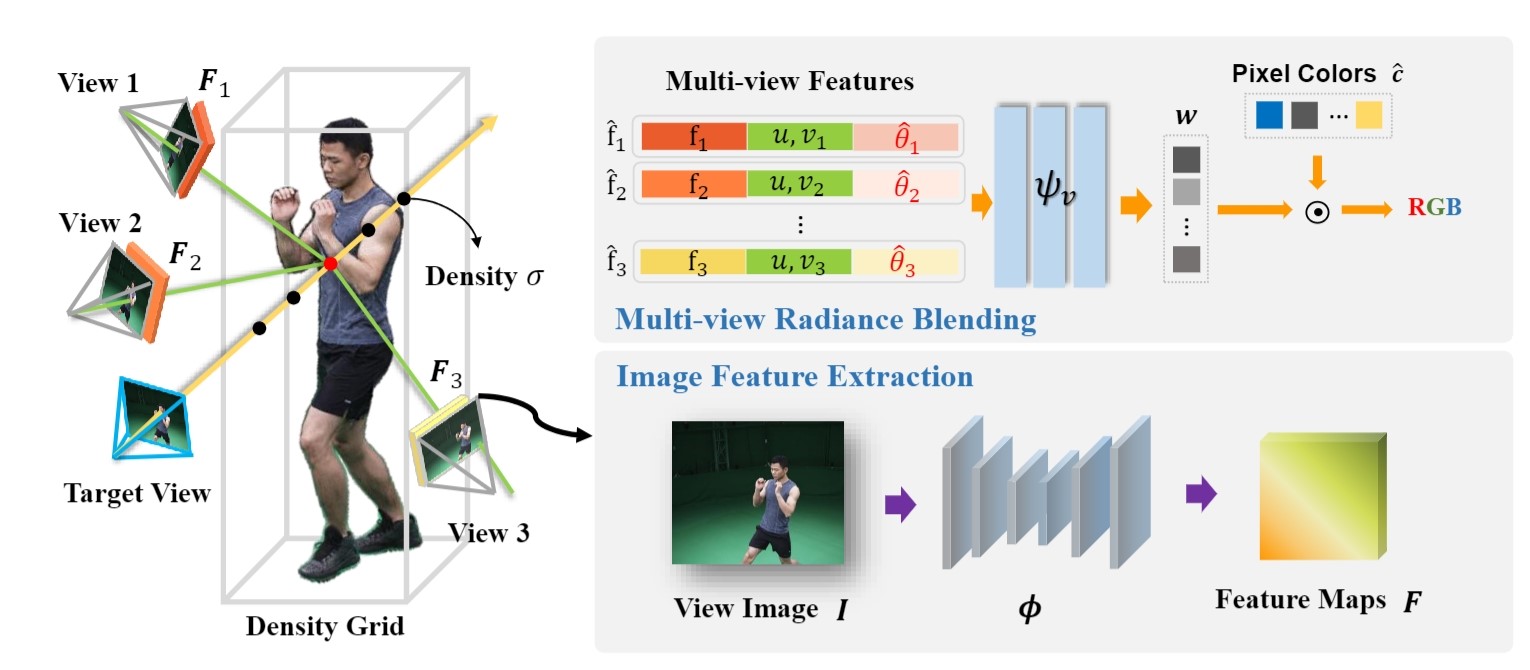
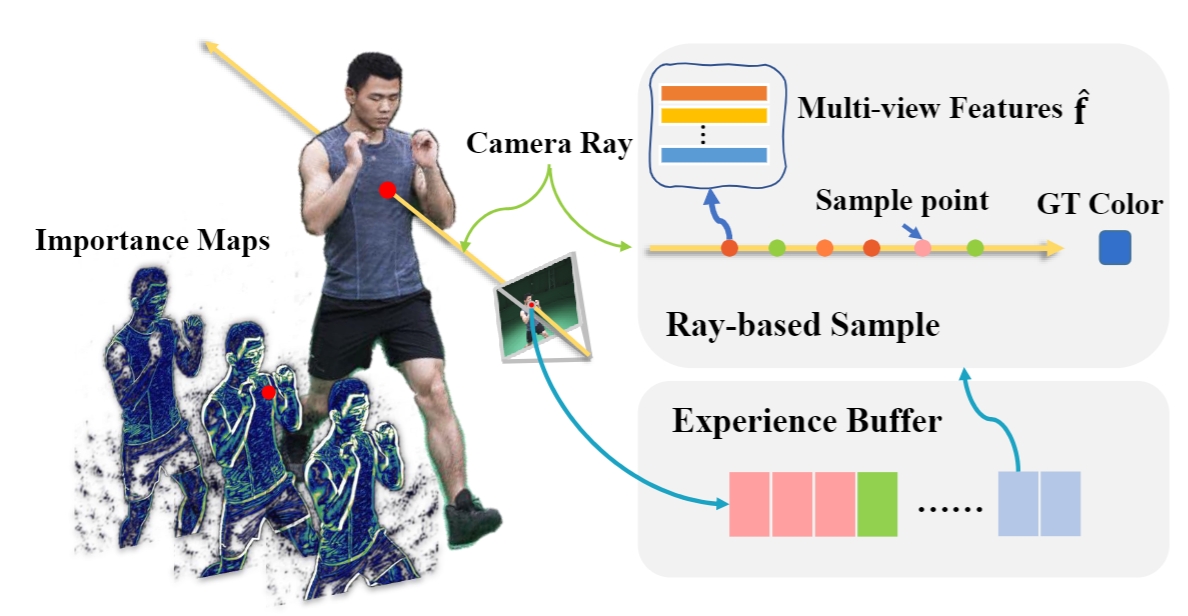
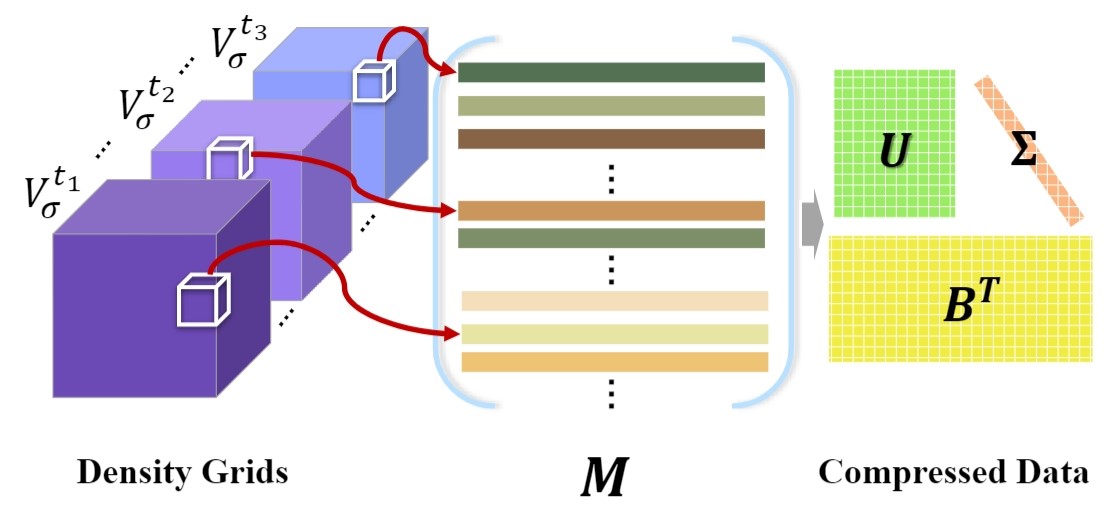
Adopting Neural Radiance Fields (NeRF) to long-duration dynamic sequences has been challenging. Existing methods struggle to balance between quality and storage size and encounter difficulties with complex scene changes such as topological changes and large motions. To tackle these issues, we propose a novel neural video-based radiance fields (NeVRF) representation. NeVRF marries neural radiance field with image-based rendering to support photo-realistic novel view synthesis on long-duration dynamic inward-looking scenes. We introduce a novel multi-view radiance blending approach to predict radiance directly from multi-view videos. By incorporating continual learning techniques, NeVRF can efficiently reconstruct frames from sequential data without revisiting previous frames, enabling long-duration free-viewpoint video. Furthermore, with a tailored compression approach, NeVRF can compactly represent dynamic scenes, making dynamic radiance fields more practical in real-world scenarios. Our extensive experiments demonstrate the effectiveness of NeVRF in enabling long-duration sequence rendering, sequential data reconstruction, and compact data storage.